
The New Faces of Fraud: How AI Is Redefining Identity, Behavior, and Digital Risk
1. Introduction – Identity Is No Longer a Fixed Attribute
The biggest shift in fraud today isn’t the sophistication of attackers – it’s the way identity itself has changed.
AI has blurred the boundaries between real and fake. Identities can now be assembled, morphed, or automated using the same technologies that power legitimate digital experiences. Fraudsters don’t need to steal an identity anymore; they can manufacture one. They don’t guess passwords manually; they automate the behavioral patterns of real users. They operate across borders, devices, and platforms with no meaningful friction.
The scale of the problem continues to accelerate. According to the Deloitte Center for Financial Services, synthetic identity fraud is expected to reach US $23 billion in losses by 2030. Meanwhile, account takeover (ATO) activity has risen by nearly 32% since 2021, with an estimated 77 million people affected, according to Security.org. These trends reflect not only rising attack volume, but the widening gap between how identity operates today and how legacy systems attempt to secure it.
This isn’t just “more fraud.” It’s a fundamental reconfiguration of what identity means in digital finance – and how easily it can be manipulated. Synthetic profiles that behave like real customers, account takeovers that mimic human activity, and dormant accounts exploited at scale are no longer anomalies. They are a logical outcome of this new system.
The challenge for banks, neobanks, and fintechs is no longer verifying who someone is, but understanding how digital entities behave over time and across the open web.
2. The Blind Spots in Modern Fraud Prevention
Most fraud stacks were built for a world where:
- identity was stable
- behavior was predictable
- fraud required human effort
Today’s adversaries exploit the gaps in that outdated model.
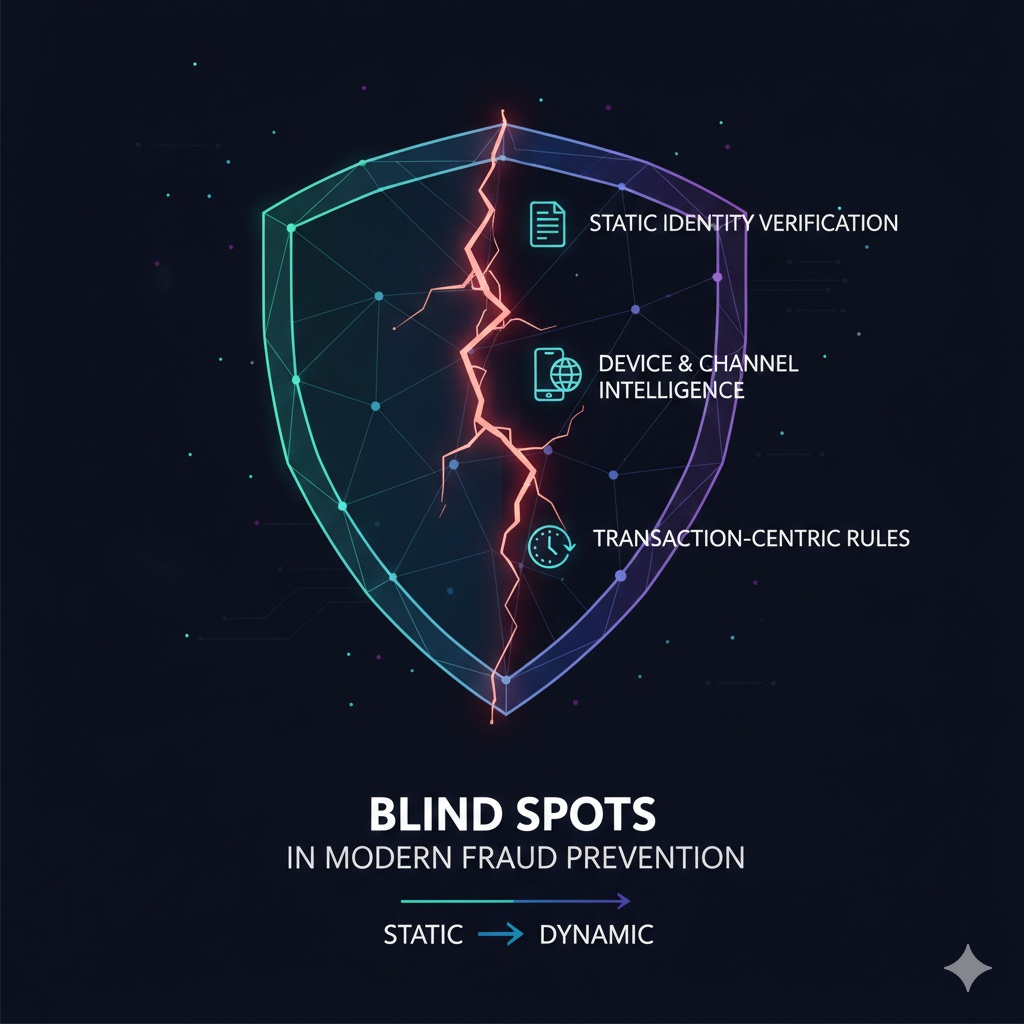
Blind Spot 1 — Static Identity Verification
Traditional KYC treats identity as fixed. Synthetic profiles exploit this entirely by presenting clean credit files, plausible documents, and AI-generated faces that pass onboarding without friction.
Blind Spot 2 — Device and Channel Intelligence
Legacy device fingerprinting and IP checks no longer differentiate bots from humans. AI agents now mimic device signatures, geolocation drift, and even natural session friction.
Blind Spot 3 — Transaction-Centric Rules
Fraud rarely begins with a transaction anymore. Synthetics age accounts for months, ATO attackers update contact information silently, and dormant accounts remain inactive until the moment they’re exploited.
In short: fraud has become dynamic; most defenses remain static.
3. The Changing Nature of Digital Identity
For decades, digital identity was treated as a stable set of attributes: a name, a date of birth, an address, and a document. The financial system – and most fraud controls – were built around this premise. But digital identity in 2025 behaves very differently from the identities these systems were designed to protect.
Identity today is expressed through patterns of activity, not static attributes. Consumers interact across dozens of platforms, maintain multiple email addresses, replace devices frequently, and leave fragmented traces across the open web. None of this is inherently suspicious – it’s simply the consequence of modern digital life.
The challenge is that fraudsters now operate inside these same patterns.
A synthetic identity can resemble a thin-file customer.
An ATO attacker can look like a user switching devices.
A dormant account can appear indistinguishable from legitimate inactivity.
In other words, the difficulty is not that fraudsters hide outside normal behavior – it is that the behavior considered “normal” has expanded so dramatically that older models no longer capture its boundaries.
This disconnect between how modern identity behaves and how traditional systems verify it is precisely what makes certain attack vectors so effective today. Synthetic identities, account takeovers, and dormant-account exploitation thrive not because they are new techniques, but because they operate within the fluid, multi-channel reality of contemporary digital identity – where behavior shifts quickly, signals are fragmented, and legacy controls cannot keep pace.
4. Synthetic IDs: Fraud With No Victim and No Footprint
Synthetic identities combine real data fragments with fabricated details to create a customer no institution can validate – because no real person is missing. This gives attackers long periods of undetected activity to build credibility.
Fraudsters use synthetics to:
- open accounts and credit lines,
- build transaction history,
- establish low-risk behavioral patterns,
- execute high-value bust-outs that are difficult to recover.
Why synthetics succeed
- Thin-file customers look similar to fabricated identities.
- AI-generated faces and documents bypass superficial verification.
- Onboarding flows optimized for user experience leave less room for deep checks.
- Synthetic identities “warm up” gradually, behaving consistently for months.
Equifax estimates synthetics now account for 50–70% of credit fraud losses among U.S. banks.
What institutions must modernize
One-time verification cannot identify a profile that was never tied to a real human. Institutions need ongoing, external intelligence that answers a different question:
Does this identity behave like an actual person across the real web?
5. Account Takeover: When Verified Identity Becomes the Attack Surface
Account takeover (ATO) is particularly difficult because it begins with a legitimate user and legitimate credentials. Financial losses tied to ATO continue to grow. VPNRanks reports a sustained increase in both direct financial impact and the volume of compromised accounts, further reflecting how identity-based attacks have become central to modern fraud.
Fraudsters increasingly use AI to automate:
- credential-stuffing attempts,
- session replay and friction simulation,
- device and browser mimicry,
- navigation patterns that resemble human users.
Once inside, attackers move quickly to secure control:
- updating email addresses and phone numbers,
- adding new devices,
- temporarily disabling MFA,
- initiating transfers or withdrawals.
Signals that matter today
Early indicators are subtle and often scattered:
- Email change + new device within a short window
- Logins from IP ranges linked to synthetic identity clusters
- High-velocity credential attempts preceding a legitimate login
- Sudden extensions of the user’s online footprint
- Contact detail changes followed by credential resets
The issue is not verifying credentials; it is determining whether the behavior matches the real user.
6. Dormant Accounts: The Silent Fraud Vector
Dormant or inactive accounts, once considered low-risk, have become reliable targets for fraud. Their inactivity provides long periods of concealment, and they often receive less scrutiny than active accounts. This makes them attractive staging grounds for synthetic identities, mule activity, and small-value laundering that can later escalate.
Fraudsters use dormant accounts because they represent the perfect blend of low visibility and high permission: the infrastructure of a legitimate customer without the scrutiny of an active one.
Why dormant ≠ low-risk
Dormant accounts are vulnerable because of their inactivity – not in spite of it.
- They bypass many ongoing monitoring rules.
Most systems deprioritize accounts with no transactional activity. - Attackers can prepare without triggering alerts.
Inactivity hides credential testing, information gathering, and initial contact-detail changes. - Reactivation flows are often weaker than onboarding flows.
Institutions assume returning customers are inherently trustworthy. - Contact updates rarely raise suspicion.
A fraudster changing an email or phone number on a dormant account is often treated as routine. - Fraud can accumulate undetected for long periods.
Months or years of dormancy create a wide window for planning, staging, and lateral movement.
Better defenses
Institutions benefit from:
- refreshing identity lineage at the moment of reactivation,
- updating digital-footprint context rather than relying on historical data,
- linking dormant accounts to known synthetic or mule clusters.
Dormant ≠ safe. Dormant = unobserved.
7. How Modern Fraud Actually Operates (AI + Lifecycle)
Fraud today is not opportunistic. It is operational, coordinated, and increasingly automated.
How AI amplifies fraud operations
AI enables fraudsters to automate tasks that were once slow or manual:
- Identity creation: synthetic faces, forged documents, fabricated businesses
- Scalable onboarding: bots submitting high volumes of applications
- Behavioral mimicry: friction simulation, geolocation drift, session replay
- Customer-support evasion: LLM agents bypassing KBA or manipulating staff
- OSINT mining: automated scraping of breached data and persona fragments
This automation feeds into a consistent operational lifecycle.
The modern fraud lifecycle
- Identity Fabrication
AI assembles identity components designed to pass onboarding. - Frictionless Onboarding
Attackers target institutions with low-friction digital processes. - Seasoning or Dormancy
Accounts age quietly, building legitimacy or remaining inactive. - Account Manipulation
Email, phone, and device updates prepare the account for monetization. - Monetization & Disappearance
Funds move quickly – often across jurisdictions – before detection.
Most institutions detect fraud in Stage 5. Modern prevention requires detecting divergence in Stages 1–4.
8. Rethinking Defense: From Static Checks to Continuous Intelligence
Fraud has evolved from discrete events to continuous identity manipulation. Defenses must do the same. This shift is fundamental:
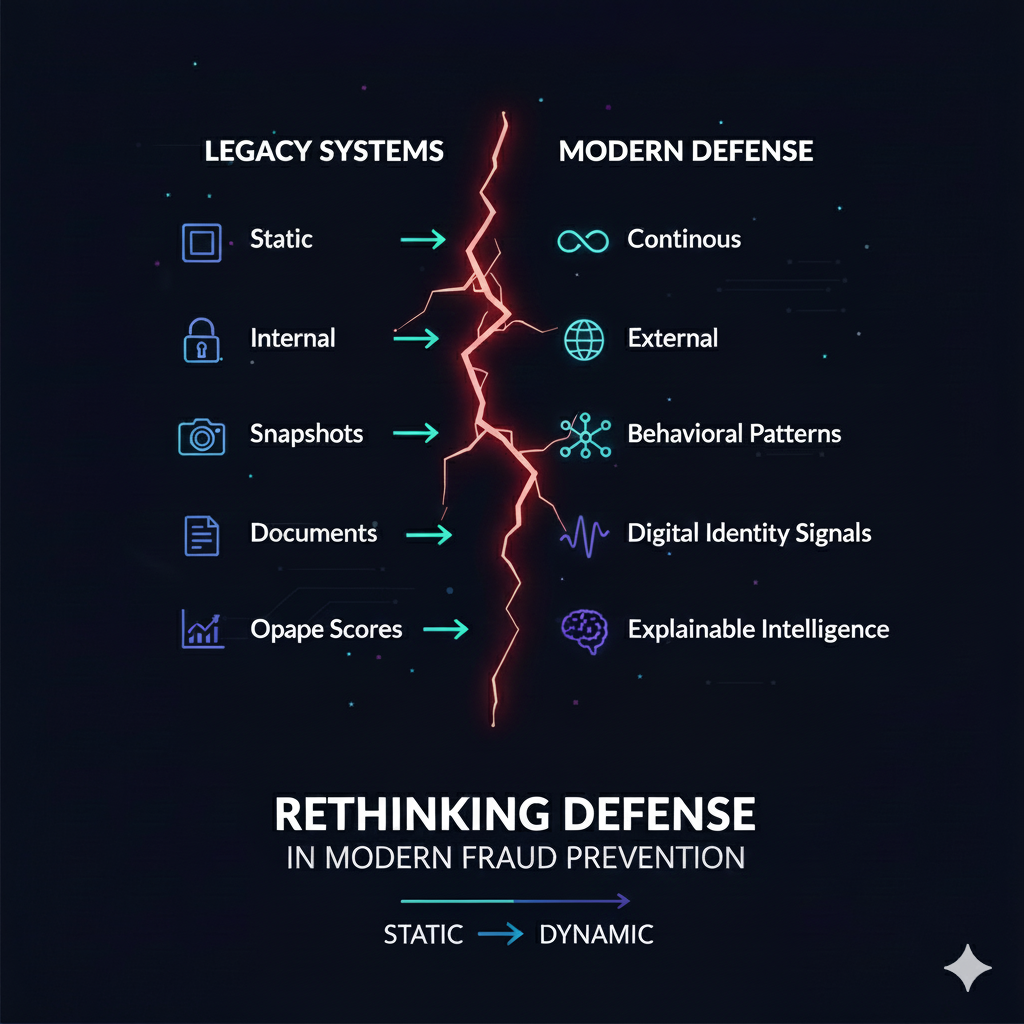
Institutions must understand identity the way attackers exploit it – as something dynamic, contextual, and shaped by behavior over time.
9. Conclusion
Fraud is becoming faster, more coordinated, and scaling at levels never seen before. Institutions that adapt will be those that begin viewing it as a continuously evolving system.
Those that win the next phase of this battle will stop relying on static checks and begin treating identity as something contextual and continuously evolving.
That requires intelligence that looks beyond internal systems and into the open web, where digital footprints, behavioral signals, and online history reveal whether an identity behaves like a real person, or a synthetic construct designed to exploit the gaps.
At Heka Global, our platform delivers real-time, explainable intelligence from thousands of global data sources to help fraud teams spot non-human patterns, identity inconsistencies, and early lifecycle divergence long before losses occur.
In an AI-versus-AI world, timing is everything. The earlier your system understands an identity, the sooner you can stop the threat.
Ready to See What Others Miss?
Resources Post

The Family Tree that Changed a Death Benefit Review
When a pension scheme contacted the son of a deceased member, the case initially appeared straightforward.
He confirmed his father had died and said he was the member’s only child. With no obvious reason to question the information, the scheme could easily have continued its entitlement review based on his account alone.
But it wasn’t the full story.
When Heka mapped the deceased member’s family network, we identified other surviving children – people who had not been disclosed and whom the scheme may otherwise never have known existed.
What appeared to be a simple beneficiary case had exposed a significant risk: a potential beneficiary attempting to position himself as the sole surviving child.
For trustees, this is the uncomfortable reality behind some deceased-member cases. Finding one relative does not necessarily mean that the full family has been found.
A contact is not the same as a complete family picture
When a member dies, schemes often begin with the information already held on file: an expression of wish form, a historic address, a named spouse or the details of one known child.
If that person responds, the case can feel as though it is moving towards resolution. But the first relative reached is only one source of information– and they may not know, remember or choose to disclose the member’s complete family circumstances.
Families are rarely as simple as the records suggest. Members may have:
- Children from previous relationships
- Estranged relatives
- Family members who have changed their names
- Children or siblings living overseas
- Grandchildren who may need to be considered
- Relationships that were never recorded by the scheme
In some cases, the information provided may be incomplete through honest mistake. In others, as our investigation suggested, someone may have a financial reason to leave another relative out.
The challenge for trustees is not simply to locate someone connected to the deceased member. It is to establish a sufficiently complete and evidenced picture of the family before making an entitlement decision.
The risk grows across large deceased-member portfolios
A single complex case can often be escalated for specialist investigation. The operational difficulty becomes much greater when a scheme is managing tens, hundreds or even thousands of deceased-member records.
Each case may require the team to answer a series of questions:
Who are the surviving relatives? Are there other children or family branches that have not been disclosed? Are the contact details still current? Has anyone moved overseas? What evidence supports the relationships identified?
Trying to resolve these questions manually, one case at a time, is slow and resource-intensive. It can also lead to inconsistent outcomes: some cases receive extensive investigation, while others depend heavily on the quality of the information already held or supplied by the first person contacted.
Older cases can be particularly difficult. Contact details may be obsolete, family structures may have changed, and relatives may now be spread across several countries. Without a systematic way to reconstruct the family network, important people can remain invisible.
This creates three connected risks for schemes:
- Benefits may be distributed without all potential beneficiaries being identified.
- Cases may remain unresolved because the available member data appears insufficient.
- Trustees may lack the supporting evidence needed to demonstrate how the family was identified and reviewed.
From tracing an individual to mapping the family
Traditional tracing often focuses on finding a named person. Family tree tracing begins with a different question:
Who else should the scheme know about?
Heka starts with the deceased member and reconstructs the wider family network around them. Depending on the case, this may include a spouse or partner, children, siblings, grandchildren and relatives living overseas.
For each portfolio, Heka can provide:
- A verified family network identifying potential beneficiaries
- Current contact information for located relatives
- Identification of relatives living outside the UK
- Supporting evidence for the relationships found
- Clear findings to support the scheme’s own entitlement review
The aim is not to make the trustee’s decision. It is to give trustees a more complete and accurate evidence base on which to make it.
This distinction matters. Family circumstances can be complicated, and entitlement decisions remain subject to the scheme’s rules and trustee discretion. But those decisions are only as informed as the family picture available at the time.
What the undisclosed children changed
Returning to the original case, Heka’s findings did more than produce additional names.
They changed the basis of the review.
Without independent family tree tracing, the scheme might have proceeded on the assumption that the son was the deceased member’s only child. Once the other children were identified, the trustees had a more complete view of the family and could investigate the case appropriately before reaching a decision.
It is a strong example of why beneficiary identification should not rely solely on what one relative says– even when that person appears credible and the case initially seems uncomplicated.
The greatest risk is not always an untraceable person. Sometimes, it is the person the scheme does not yet know it needs to trace.
A portfolio-wide approach to deceased-member reviews
For schemes holding large portfolios of deceased members, family tree tracing can be applied across the full population rather than reserved only for individual cases that have already become problematic.
This allows schemes to:
- Progress more deceased-member cases in parallel
- Identify missing branches of a family before contacting potential beneficiaries
- Prioritise cases requiring deeper investigation
- Reduce reliance on unverified statements from individual relatives
- Create a clearer evidence trail for entitlement reviews
Instead of waiting for inconsistencies to emerge case by case, schemes can develop a more complete view of each deceased member’s family from the outset.
Because when a relative says, “I’m the only one,” the scheme should be able to verify whether that is really true.
Managing a portfolio of deceased members? Heka can map and verify family networks at scale, helping your team identify potential beneficiaries and move entitlement reviews forward with greater confidence.

The Modern Fraud Stack: How Decisions Actually Get Made (and Where They Break)
An enterprise-grade fraud stack is not a product. It is a latency-constrained decisioning system in which multiple layers – data collection, identity validation, enrichment, scoring, and decisioning – operate as a single flow. In most transaction environments, that entire loop runs in under 300 milliseconds for transaction decisions, and only marginally longer for onboarding.
The challenge is not assembling the stack. Most institutions already have the core components in place, often across multiple vendors and internal systems. The challenge is understanding how those components interact in practice – and where the system produces decisions that appear well-supported, but are not.
How Fraud Decisions Are Produced
A fraud decision is not generated by a single model or rule. It is the result of a sequence of stages, each contributing a different type of signal or constraint.
At a high level, the system collects observable signals, validates identity claims, enriches those signals with external data, applies probabilistic scoring, enforces deterministic rules, and aggregates all outputs into a final decision. Cases that fall outside clear thresholds are escalated, and outcomes are fed back into the system to continuously refine performance.
This flow is consistent across financial institutions, even where implementation details differ . What varies is the relative strength of each layer, and the degree to which each one contributes meaningful signal to the final decision.
The 8 Layers of the Fraud Stack
In practice, this decisioning flow can be broken down into eight functional layers:
1. Signal Collection
The system captures all observable inputs at the point of interaction, including device fingerprinting, IP intelligence, behavioral biometrics, and identity data. These signals form the raw input for all downstream analysis.
2. Identity Verification (IDV)
Identity attributes are validated against trusted sources such as credit bureau headers, SSA records, and sanctions lists. This establishes whether the identity exists and meets regulatory requirements.
3. Data Enrichment
External data sources are used to expand the identity profile. This includes email intelligence, phone intelligence, address validation, and consortium-based signals that provide additional context beyond the initial claim.
4. Risk Scoring
Machine learning models transform raw and enriched signals into probabilistic risk scores. These models typically target specific fraud types, including application fraud, synthetic identity fraud, and account takeover.
5. Rules Engine
Deterministic rules enforce policy and known fraud patterns. These include hard blocks (e.g., sanctions matches), velocity thresholds, and mismatch conditions that cannot be fully captured by models.
6. Orchestration & Decisioning
All signals, model outputs, and rule evaluations are aggregated into a final decision – approve, review, or decline – through a centralized decisioning layer.
7. Step-Up & Case Management
Cases that fall into intermediate risk bands are escalated through additional verification (e.g., biometric checks, OTP) or routed to human investigation workflows.
8. Feedback & Model Governance
Confirmed fraud outcomes, false positives, and analyst decisions are fed back into the system to retrain models, refine rules, and monitor performance over time.
This architecture is broadly consistent across the industry. The presence of these layers, however, does not guarantee effective decisioning.
A Practical View of Where Each Layer Contributes (and Where It Breaks)
The following simplified view highlights how each layer contributes to the final decision, and where its limitations typically emerge:

This view is intentionally reductive. Its purpose is not to describe the system exhaustively, but to make visible where signal strength and decision confidence can diverge.
Where Modern Fraud Stacks Fail
Failures rarely occur because a layer is absent. They occur when a layer produces an output that appears sufficient, but lacks underlying depth.
An identity may pass bureau and SSA validation, present no device or velocity risk, and return acceptable enrichment signals. Yet the identity may still lack coherence across time – no consistent footprint, no reinforcing signals, and no evidence of persistence.
This is the central gap.
Most stacks are effective at confirming that an identity exists. Many can confirm that a user is physically present. Far fewer can determine whether the identity behaves like a reliable individual over time.
Structural Drivers of These Gaps
These limitations are not purely technical. They are structural.
Latency constraints limit the ability to incorporate deeper or slower data sources. Scale requires reliance on generalized models rather than case-specific analysis. Cost and conversion pressures reduce tolerance for additional friction or enrichment calls.
As a result, systems tend to emphasize:
- structural validation (existence)
- reactive signals (prior exposure)
Both are necessary. Neither is sufficient to fully resolve identity risk.
Why Fraud Stacks Differ in Practice
The “perfect” fraud stack is a myth. In practice, every stack reflects a set of trade-offs – between latency, cost, scale, and risk tolerance. Different institutions prioritize different parts of the system:

From Architecture to Evaluation
Understanding the structure of a fraud stack is necessary, but not sufficient. The more important task is evaluating how the stack behaves under real conditions.
Key questions include:
- Which layers are driving final decisions?
- Where is the system relying on structural validation alone?
- Which signals appear present, but are not materially influencing outcomes?
Fraud does not typically exploit missing components. It exploits the assumptions created by partial signal coverage.
Next: Evaluating the Stack in Practice
This report provides a structural view of the modern fraud stack. In the accompanying evaluation guide, we extend this framework to:
- assess the relative strength of each layer
- identify signal gaps and over-dependencies
- map vendor capabilities across the stack
- and isolate the conditions under which structurally valid identities continue to pass controls
Follow us to be notified when the full evaluation guide is released.

Undetected Deaths in Pension Member Records
A recent data review identified deceased members still recorded as active – including deaths dating back to 2002.

A recent pension data cleanse for a large UK industrial defined benefit scheme identified that approximately 2% of members were deceased, including several individuals whose deaths dated back more than twenty years.
Two members recorded as active in the scheme records were found to have died in 2002.
For large defined benefit schemes, discrepancies of this scale can represent a material number of member records requiring validation before insurer pricing can proceed.
No administrative exception had been raised. The discrepancy only became visible once member records were validated against external sources.
These findings illustrate how member data inaccuracies can remain embedded within scheme records for extended periods without triggering operational alerts.

Insurer due diligence
When schemes approach buy-in or buy-out transactions, insurers undertake detailed due diligence on the member population. Confidence in the integrity of scheme data therefore becomes an important consideration.
Insurers typically review several areas, including:
- mortality status
- member identity validation
- geographic location of members
- completeness of contact records
- accuracy of benefit entitlements
Where information cannot be independently validated, additional verification work may be required before pricing can be confirmed. In some cases this can extend transaction timelines or introduce further assumptions into pricing models.
The Pensions Regulator also emphasises that trustees are responsible for maintaining complete and accurate member data as part of effective scheme governance.
Why data gaps occur
Pension schemes operate over long time horizons. Member records may remain in administrative systems for several decades and often pass through multiple administrators and technology platforms.
Over time, several structural issues can arise. Members may pass away without the scheme being notified, particularly where contact with the scheme has been lost.
In England and Wales alone, over half a million deaths are registered each year, according to the UK Office for National Statistics (ONS). Reconciling long-standing member records against this scale of national mortality data is therefore an important element of maintaining accurate scheme populations.
Increasing international mobility also reduces visibility within domestic datasets. Addresses and contact details may remain unchanged for extended periods, and historical system migrations can introduce inconsistencies across records.
These issues do not necessarily affect day-to-day administration but can become visible when scheme data is examined more closely during transaction preparation.
External validation sources
To address these risks, schemes increasingly supplement internal records with additional verification sources such as:
- Civil registration data, including GRO death records
- Probate filings and estate notices
- Online obituary publications
- Open-web signals, including professional networks and social media activity
Platforms such as Heka help consolidate these signals into structured intelligence. This allows schemes to validate member records, identify mortality indicators, and improve confidence in the accuracy of their member population.
Conclusion
Undetected deaths in scheme records illustrate a broader issue: member data can deteriorate silently over time.
Routine administrative processes may not surface these discrepancies. However, when schemes approach buy-in or buy-out preparation, such gaps can become operationally and financially relevant.
Early validation of member data can therefore reduce uncertainty, support insurer due diligence, and improve readiness for endgame transactions.